Blog
All Blog Posts | Next Post | Previous Post

 Extend TMS WEB Core with JS Libraries with Andrew:
Extend TMS WEB Core with JS Libraries with Andrew:
Database Image Handling
Tuesday, May 9, 2023

Motivation.
In a traditional VCL application, images in a database might be returned in binary form by a query of some kind (a blob) and then shown on a form, typically with a TImage descendant used to handle the display. There isn't anything immediately or automatically available to optimize this situation. We could build our own caching system so that we don't have to repeatedly download the same images all the time, keeping a copy in a local temp folder, for example.
But in a typical client/server environment, where perhaps there aren't a lot of images in play, this might not even be much of an issue. Perhaps the images in the database would be stored as a reference to a location on a network storage device rather than a blob. The client would then just load them directly from that network storage device using the location reference. Pretty standard fare, has lots of options, and not too difficult to implement at all.
In the browser environment, however, there are a few key differences.
- There's a tendency to use images more often and for more things. In part, this is just a natural evolution
of apps generally, benefiting from having the necessary capacity and capabilities to handle more image data
(and formats) without negatively impacting performance. We're starting to see more and more apps have video
incorporated in a similar way, for similar reasons.
- Remote web apps don't always have the same level of connectivity as, say, a native app running in a LAN
environment. Accessing a "shared network storage device" is suddenly a non-trivial thing. And we'd really
rather limit the various paths for data to flow into and out of an organization. Both for performance and
security, given that access likely originates entirely outside a protected network, very different from a
controlled LAN environment.
- Browsers have evolved to have substantial image-handling capabilities all their own that we can take advantage of without adding complexity to our own client apps. Image caching is a pretty big help here, but also the ability to easily display whatever images we like, in any arrangement we like, is now far simpler. And, if properly managed, can be very quick as well.
With a TMS WEB Core app, we can actually develop a project any way we like - at either end of the spectrum, or anywhere between. For example, we could just retrieve images from a database and display them using a TWebImage component, without any consideration at all for the browser environment, just as if we were developing a VCL app. Or we could develop a project that bears very little resemblance to that at all, taking advantage of all that the browser has to offer.
And there are no doubt projects that may work best with some combination of all
of these things. This is far from a "best practices" guide. Rather, this is more of an exploration of the many
choices available to you as the developer of a modern web application when using TMS WEB Core.
Image Data.
In this context, the images we're referring to are typically BMP, JPG, or PNG images that originated as an actual file somewhere, like from a camera, or perhaps were created using something like Adobe Photoshop. Doesn't really matter. The point is that they were originally files, with a specific filename, resolution, size, and other image-specific attributes, and we'd like them to be included in our application in some form or other. So we need to move them from wherever they are, into our application.
If there are many related files, then they are likely to be stored in a common location. This might be a folder on some remote server somewhere, or perhaps in a folder that is part of the application directly, stored in the same folders as the rest of the JavaScript, HTML, and CSS that make up a modern web application. Or perhaps these files are stored in fields in a database that our application has access to. Also doesn't really matter. What does matter is that we at least know where the actual image data is and that we have a path of some kind between our application and that image data.
Ultimately, the image data has to find its way to our application. But even here, there is a bit of a divergence from our traditional VCL environment. The traditional approach might be to get this image data via a REST API, where TMS XData is our REST API server of choice. In that scenario, the data might flow into our app by way of a JSON conduit, where we have to make an explicit request, and then process the response, to get at the image data.
As JavaScript isn't multi-threaded, this is an effort that has the potential to use up
resources we might put to better use elsewhere. But browsers also have a built-in mechanism for retrieving
image data entirely outside the scope of our JavaScript application. By creating <img> tags on the page
and assigning a src attribute as a remote URL, the browser will happily go off and download the actual image
data asynchronously, and update the element on the page when it is ready. And, crucially, it can do this using as many separate threads as it likes, for as many images as we choose to define - potentially thousands - without having much impact on our
application at all. This is a tremendously powerful part of the browser environment that we would not want to
overlook without good reason.
For our purposes today, we're going to assume that our application is talking to a database, and the database
will be providing access to the images. It may provide the actual image data, or it may provide an image
reference of some kind that we then have to use to get to the actual image data. But ultimately it is the
database that provides the data we need. For TMS WEB Core projects that need to access a database, it is very
convenient to use a REST API server like XData, so we'll assume that's what we've got. It is also very
convenient to handle data that is coming back from such a server when it is formatted as JSON. So let's start
with that and see where it goes.
Data URIs.
JSON as a format is good at managing text data, but not so good at managing binary data. Instead, anything binary-related gets converted into a string, typically using something like Base64 encoding. Any file of any type can be converted back and forth between a binary file and a Base64-encoded file. And we have tools to do this conversion back and forth, both in TMS WEB Core client and TMS XData server environments. Some databases even have direct support for encoding/decoding Base64 data as well.
Taking this a bit further, we can
represent those original binary image files as a string by converting them into a Data URI. This is basically a
Base64-encoded file (that is now a string), with a prefix that describes what it is. For example, one of the
smallest PNG files possible, one transparent pixel, might look like this, when converted into a Data URI (aka Data URL).
Any image format can be converted into a Data URI because it is just that - a Base64 encoded string with a prefix. If we wanted this image displayed on a page, we just need to add it as the "src" attribute in an <img> tag. Note that every other image we'll likely encounter will be a longer string, often much, much longer, perhaps several MB in length. But the exact same mechanism works just as well, regardless of the image size. To display it on the page, we would just add an HTML element like this. The src attribute can also be assigned to the URL property of a TWebImage component - this would be rendered as HTML in a similar way.
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAACklEQVR42mMAAQAABQABoIJXOQAAAABJRU5ErkJggg==">
An image added in this fashion would then be displayed at whatever native resolution it was created at, within the confines of how the <img> tag is placed on the page. If we wanted to change the dimensions of the image visually, we could do so by adding "width" and "height" attributes to the <img> tag, or by applying any number of CSS rules or a variety of HTML structures to the mix.
The point, though, is that it is this string that we're after - the src attribute - as this is what the browser uses to figure out what it needs to render on the page. For Data URIs, the browser has everything it needs - it will automatically decode the Base64 string into an image and display it directly, without having to go off and download anything else.
In fact, it would be kind of handy if the database field actually just stored the <img> tag itself as
well. This way, we could just add the contents of the database field directly to a <div> element, and it
would be rendered directly. This is essentially what we did originally with the ChatGPT images. The OpenAI API
returns the images it generates as Base64 PNG files. So we just added the <img src="data:image/png;base64,"
prefix, and the "> suffix, and stored the value in the database, like this:
Query1.ParamByName('GENERATEDIMAGE').AsString := '<img src="data:image/png;base64,'+(((ResultJSON.GetValue('data') as TJSONArray).Items[i] as TJSONObject).GetValue('b64_json') as TJSONString).Value+'">';Later, when it came time to display this image in the client, we just took the value and dropped it into a <div> element like this, where we also added a title and some other classes to the enclosing <div> element. This could have also been accomplished by storing the Data URI without the <img> tag bits and creating the <img> tag at run time instead of nesting it in a <div>. Lots of options here.
ImageRecent.innerHTML += '<div class="cursor-pointer ViewableImage" title='+data['ImageAI Recent'][i].prompt+'>'+data['ImageAI Recent'][i].generated_image+'</div>';
Note that there's nothing in this client code that says this is a PNG file, or that it has any particular size -
the image data just passes all the way through from the original OpenAI API response, into the database, out of
the database, and onto the page. In this case, the images are only configured for a specific size when they are
rendered, which is in turn controlled by a bit of CSS, here setting them to 92px by 92px.
/* Recent ImageAI Image Thumbnails */
#ImageRecent > div > img {
width: 92px;
height: 92px;
border-radius: 0.375rem;
}This rule is being applied to the <img> tag, also without concern as to what is in the <img> tag or its src property. If our original image was much bigger than this, then there's perhaps an opportunity for optimization by only requesting an image that is, at most, 92px x 92px. If the image is much smaller than this, then it may appear blurry or pixelated when scaled up to this size.
Regardless, the browser does all the work to
sort out the image format, size, orientation, and so on. It can, as above, even round the corners or adjust
opacity or any number of other visual tweaks when displaying the image. Note again that it isn't strictly
necessary to nest the <img> inside a <div> tag - we could have just added the <img> tag
directly and adjusted it instead. On the other hand, having the extra <div> parent might make it easier to
apply certain filters or other CSS properties that can be applied against the <img> element.
This, then, is roughly one end of the spectrum. The image data that is stored directly in a field in the
database gets passed down and displayed in the client. A direct path, as far as these kinds of things go. If
the image data is substantial (or if there are many images), this can be a potential bottleneck, as it takes
time for this data to move around. Both in terms of moving image data into and out of JSON, but also in terms
of the network cost of transferring a large chunk of JSON to begin with. Not many opportunities for improvement
in this approach.
Another small variation on this might be that the image data could be stored in the database in a binary format
(BLOB) originally. In such cases, one approach would be to use SQL or another server-side coding option (like
XData) to convert the binary data coming from the database into Base64 (and potentially a Data URI or an
<img> as well) so that it could then be included in the JSON data being returned, and then handled the
same way after that. To Base64 encode data in this scenario (say, within an XData endpoint), we'd first get the
value from the database (likely as a BLOB of some flavor) and then save that to a TStream. Then we can convert
it to an encoded stream. Something like this.
procedure GetBase64Image(FieldName:String):TStream;
var
ImageData: TStream;
begin
ImageData := CreateBlobStream(Query1.FieldByName(FieldName), bmRead);
TNetEncoding.Base64.Encode(ImageStream, Result);
ImageData.Free;
end;Ultimately, we end up in the same place - the image is encoded and transferred directly through whatever database connectivity we've set up for this purpose, and the same amount of data is being passed around, more or less, based on the size of the images, large or small.
Database Image References.
Another common approach is to not store the actual image data in the database at all. Instead, the images could be stored as regular files in a common (secured) location, and the database field just indicates where the file can be found. Perhaps the database contains just a filename, and we'll "just know" that the file is located in the \\CORPORATE\PHOTOS\ folder - a shared network resource.
This greatly simplifies the database work, as we just have a small text field to deal with and no BLOB headaches. However, the setup and maintenance of this shared network resource, particularly keeping it in sync with the database, is a potential wrinkle. Our web app likely won't have direct access to that (hopefully!!) so instead our REST API server might have to go and retrieve the image from there, load it up into a TStream, convert it, and then carry on as we did previously. Not terrible, but not really much different.
Sometimes this shared network resource might actually be accessible from the client because it isn't a Samba-style file server but rather a regular web server. We could approach this the same way, where XData downloads the image from this other type of shared network resource into a TStream, converts it, and then carries on. This might be necessary if the image web server was on an intranet, not accessible from the client.
But let's assume that the client can access it. We can just pass our image as a regular URL rather than a Data
URI. For example, if we know the name of the server (likely) we could format our image, in the JSON being
returned, to just point at the file directly.
<img src="https://shared.example.com/corporate/photos/party.jpg">
When this is added to our <div> element in the browser, the browser will know to retrieve this file, issuing a new request to retrieve it from the remote website (asynchronously), and then display it using the same rules as before. If there are many images in play, without much other data, it may be that just the filename alone is included in the JSON, where the client will then have to populate the rest of the URL before adding it to the <img> tag's src attribute.
If we were displaying a list of hundreds of images, for
example, this would likely cut down the JSON being transferred, maybe down to a quarter of the size, given the
relative length of the rest of the URL. This makes for a considerably more efficient transfer of this kind of
data, even though no actual image data is included. When compared to the transfer of JSON with included image
data, this is likely a very tiny fraction of the size, maybe a few KBs as compared to potentially many MBs.
This is a very popular approach that works quite well. In fact, the Actorious project (a TMS WEB Core / TMS XData project created as part of the Tabulator blog posts, starting here) uses this extensively to retrieve and display hundreds of images immediately when the application first starts. In that project, The Movie Database is the source of the bulk of the data generally, and all of the image data specifically. When a JSON response is received from their REST API, images are included as just a filename. The rest of the URL, including options for the actual size of the image, needs to be added to the filename to get the final URL that is added to the <img> src attribute before the image can actually be displayed.
One potential hurdle here is that it may involve setting up a separate web server, in addition to the REST API
server used to access the database. The extra web server may not be a problem if you've already got one serving
up the application itself that can also be tasked with serving up images. Or it may be more involved if, like in
the case of The Movie Database, it needs to serve up so many images at such a high rate that a content
distribution network is used to meet the demand. This works particularly well when data is primarily just being
served up in a read-only fashion and performance is paramount. Additional web servers take time to configure,
secure, and maintain. Whether that's worth the effort is of course highly project-specific.
Another potential hurdle involves keeping this extra external data store in sync with the database. If a new image (or image reference) is added to the database, then, at the same time, the image file needs to be added to this other web server, typically a folder somewhere. If anything is ever out of sync, then the client will get back image references that don't link to actual images.
We'll look at a way to help with that in a little bit, but
it can be a problem, particularly if you have multiple copies of the database or multiple copies of the image
store, and frequently need to update one or the other, or both. Normally, the database itself is pretty good at
keeping its own content synchronized - this is its main purpose in life, after all. However, adding in an external
image store adds a bit of complexity that is perhaps harder to manage. Not impossible of course, just harder. Some databases may even be able to manage this themselves, so be sure to check what options are available for
your particular database.
Returning Images.
Another possibility worth exploring is to have an additional REST API endpoint that serves up an image
as a binary file directly. It would likely add just a little bit of overhead to have an XData server, for example, to add a service
endpoint that steps in to play the role of a web server, serving up images from the local filesystem or some
other shared network resource, or even from a database.
The benefit here is that we wouldn't need to set up a separate web server, or even equip an existing web server, to serve up the images - we could just let XData do it directly. For example, we could pass a filename to the endpoint and it would return the image directly, just as if it were a regular web server. In this case, the REST API request would contain a query parameter to indicate the filename of the image that we would like to retrieve. XData could then load that file and return it as a binary image.
For example, let's say we had, on our XData server, a set of PNG images in C:\Data\Images. We could then create
the simplest of endpoints to serve up files in that folder.
function TChatService.ImageTest(Filename: String): TStream;
begin
TXDataOperationContext.Current.Response.Headers.SetValue('content-type', 'image/png');
Result := TFileStream.Create('C:\Data\Images\'+Filename,fmOpenRead);
end;Here, we're telling XData (and anything connecting to it) that the data coming back is a PNG file. We could also look at the filename to determine what the image format is and adjust the content-type accordingly. If our XData server had Swagger enabled, we could even test this endpoint.
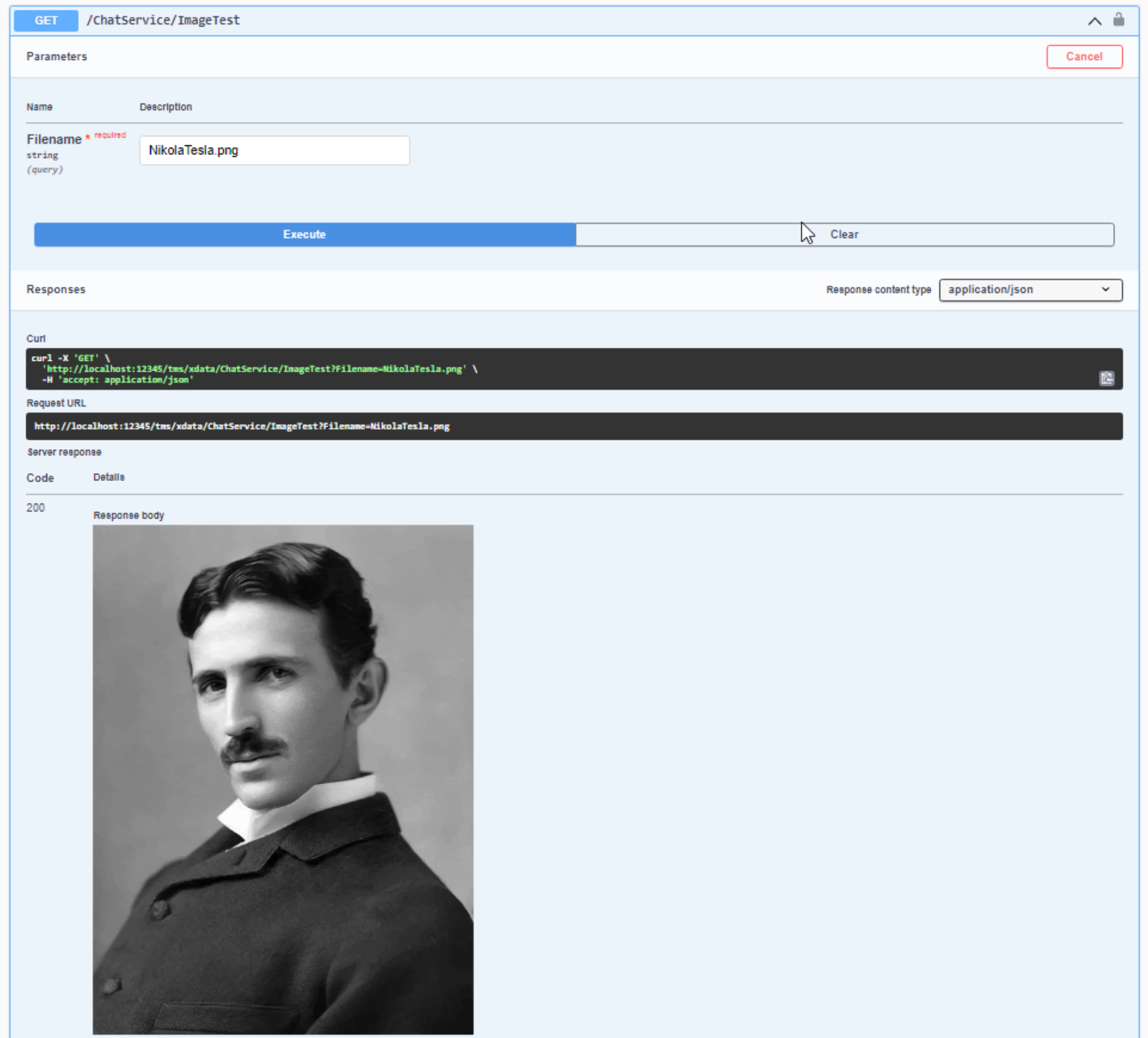
Swagger - Returning an Image.
Looking at the Swagger page, we can even see the URL that we can use to just get the image, without using any
kind of REST API interface - just the URL. We can even just copy and paste this into the browser to get the
image immediately, just as if it were a regular web server.
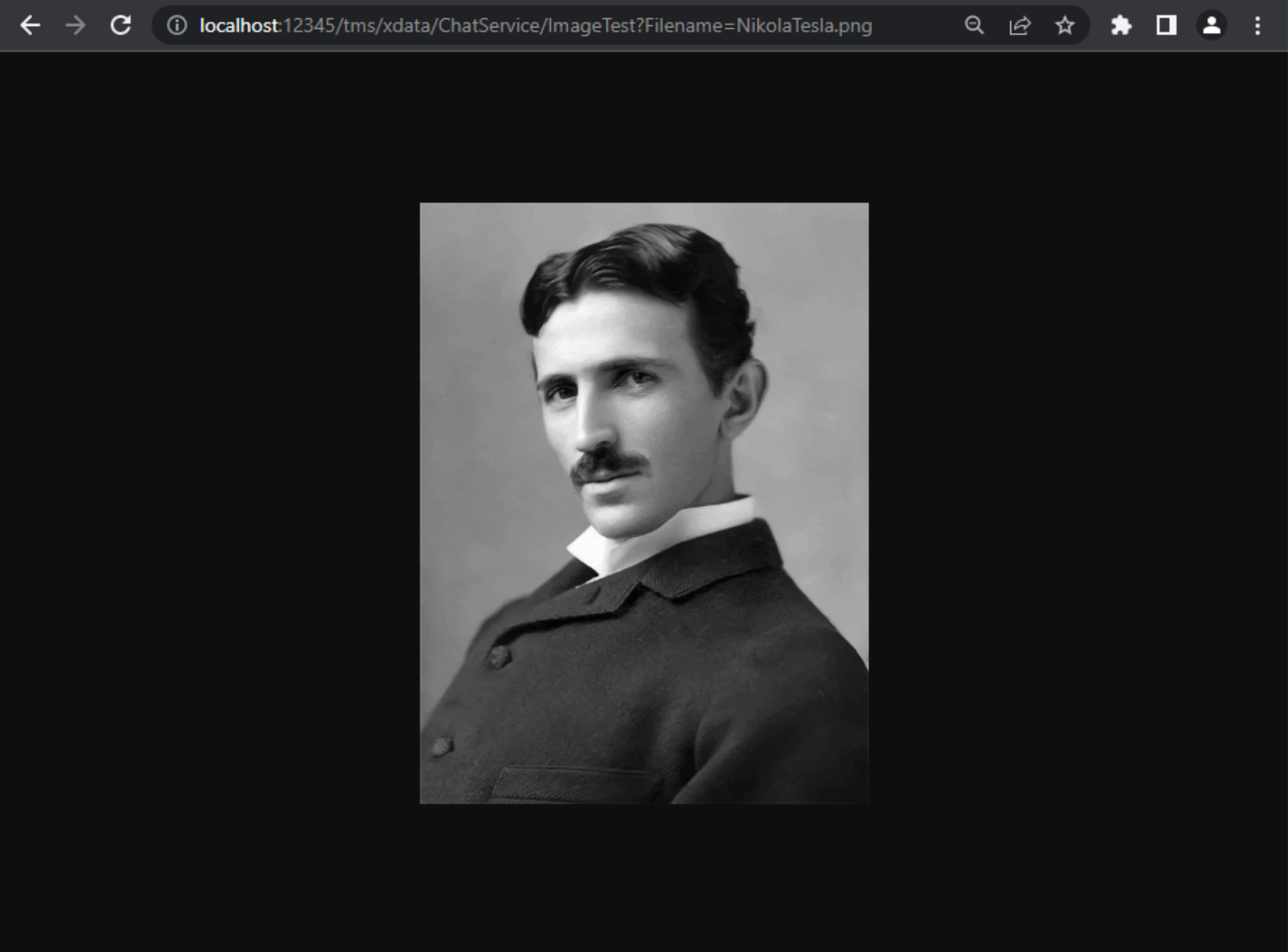
Service Endpoint as Image URL.
This works when returning one image at a time. This URL could be used as the value for the <img> src
attribute directly, bypassing the need for an extra web server, and instead using the same REST API server that
we used to get the image references in the first place. We'll see in a moment how we might use one endpoint to
return image references that are for this second endpoint.
But first, we could take this a step further and
have this same endpoint return an image in the same way, but instead of serving up a file from the local file
system, it could serve up the image after retrieving it from the database. If the database stored the images in
a binary format, they could be returned directly. If they were stored as Base64-encoded strings, they could be
converted back to binary and served up this way as well.
ImageString := Query1.FieldByName('photo').AsString;
ImageBytes := TNetEncoding.Base64.DecodeStringToBytes(Copy(ImageString,33,length(ImageString)-34));
Result := TMemoryStream.Create;
Result.WriteBuffer(Pointer(ImageBytes)^, Length(ImageBytes));Here, the image in the database is stored as an <img> tag with a Data URI. The tag itself plus the Data URL prefix/suffix need to be stripped off. The prefix is <img src="data:image/png;base64, and comes in at 33 characters, hence the choice of parameters to the Copy() function. That leaves us with the raw Base64 string which is then converted to binary and passed back as the result of the endpoint. Not quite as efficient as just serving up a local file, but pretty quick, depending on the speed of the database and the size of the images.
Image Security.
Using the above approach, we can also implement whatever level of security we want to protect access to the images. Usernames, passwords, JWTs, whatever we like, as we're essentially serving up data from a database just like any other kind of data from the same database. This applies so long as we use the usual mechanisms for accessing the REST API endpoint - IE, passing our authorization header, JWT, or whatever else we've got going on.
If we let the browser retrieve the image automatically, using its multi-threaded asynchronous mechanism,
this happens outside of JavaScript, and alas, outside of our ability to apply our authorization information
to the request. This means that if authorization is required to access the image, the image loading will
fail. The workaround for this isn't really a workaround at all. It involves making a separate request
manually, where the authorization information can be applied, converting the image to a Base64 Data URI, and
then populating the original <img> tag with that. Which is what we could do without involving the browser
anyway.
However, much of the time, images are treated a little differently in that there is often little to no security needed. This is partly because the filenames tend to be rather cryptic if you have many such images. Using something like a GUID for the filename isn't unheard of, for example. The chance that someone might "discover" an image is small.
More often, though, it is because they don't need to be read-protected, particularly if that
protection comes with a performance or convenience penalty. If you have an image store that is primarily
composed of product photos, like, say, Amazon, it doesn't really matter if they're publicly available because
the entire website is publicly available anyway. Being able to share the images broadly is far more important
than restricting them to people who have been authorized. And if you have a new unreleased product that you don't want anyone to see, having a unique GUID for a filename will mean that someone isn't likely to run across it, accidentally or otherwise.
This may also apply even in your own organization. If you want to email someone a photo from your website (or web app in this case), it is super-handy to just copy and paste the link and be on your merry way, without having to think about whether the person you're sending the image to will have to do anything to be able to view that image.
Likewise, much of the time images can be downloaded locally from the browser, at which point they
aren't governed by any policies that a web app can enforce. Some steps can be taken to protect against casual
image downloads or other websites directly linking to your images, but fully protecting images, in general, isn't
really something that can be enforced with the tools we have. Topics like copyright, watermarking, and so on
apply here.
Note that there are in fact plenty of scenarios where we'd want to enforce a layer of security to prevent
unauthorized access to image data. Perhaps you're building an accounting application and want your clients to
be able to upload images of receipts, tax or legal documentation, or even bank statements. In such cases, you'd
very likely not want to use an image endpoint and instead, only allow those images to be transferred using one of
the other approaches we covered earlier. People who have access to such images are likely the same people who
uploaded them, so not really any harm in making it easy for them, and only them, to download their own images at
a later point.
Nested Endpoints.
With that out of the way, we can explore some other options for improving the performance of our web app. I'm
calling this next one "nested endpoints" because it is kind of amusing (or kind of painful!) to think about what
that kind of implementation might actually look like from an API perspective, but in practice, it sort of follows
what we've been doing already. Originally, we were requesting a set of images from an XData (or REST API)
endpoint (let's call it the GetManyImages endpoint), and getting a response that had the images, either as the
Base64-encoded image Data URI or a regular URL that points at a web server or perhaps another REST API endpoint.
We've had a look at how to make the same XData server return an image as a binary file that can be accessed directly via a URL. Let's call that endpoint GetOneBinaryImage. We can therefore combine these two, populating the URLs returned in GetManyImages with URLs that reference GetOneBinaryImage. When we get the response from GetManyImages and populate our web page with <img> tags that have the GetOneBinaryImage URLs in them, the browser will then issue requests for those images to our very same XData server to retrieve the binary images. So... nested. Just like I said.
What is really quite fun about this is that we can do a switcheroo here, entirely without making any changes to the client code at all, and get a huge boost in performance. Let's see how this works.
Let's say we're going
to make a request for 25 images, and each Image is large, say 1 MB. For reference, OpenAI's generated PNG images
come in around 200 KB for their 256x256 resolution, around 800 KB for their 512x512 resolution, and around 3MB
for their 1024x1024 resolution. Let's assume that the Base64 size is about the same as the binary size. In
reality, it is more like 33% larger. If the compression middleware is added to XData, this drops to around 5%,
so not such a big deal. Let's say we want to serve images directly from our database, perhaps stored as Base64
<img> tags.
When we make a request of our GetManyImages endpoint, we'll ask for the most recent 25 images, along with their index values and descriptions. We might get back a JSON array that lists the index value and description along with the Base64-encoded images themselves, so a roughly 25 MB JSON file will be returned. The index values and descriptions might add up to a few KB at most, hardly noticeable, and even that is only if we had really long descriptions.
We can then copy each of the 25 <img> elements onto our page, and the images will be
displayed. However, we'll have to wait for that 25 MB JSON file to arrive before we can do anything. When it
arrives, we can very quickly display all of the images at once because we have all of the data. The JSON might
have entries that look like this.
[...
{"ImageID":1234,"Desc":"<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAACklEQVR42mMAAQAABQABoIJXOQAAAABJRU5ErkJggg==\">"},
...]Now, instead of returning the image data as Base64-encoded text inside the JSON, let's instead return a URL that references our GetOneBinaryImage endpoint. Our JSON now only contains the index value and description along with a URL. So still only a few KB in total instead of 25 MB. What do we use for the URL? In the SQL that we use to generate the rest of the data (the index value and description), we can formulate a URL by passing in a URL prefix, and just appending the index value to it, as we'll use the index value in the same way we were using "filename" in the previous examples. So our SQL might look like this.
SQL.Add('SELECT '+
' ImageID '+
' Desc, '+
' "<img src="||:URL||ImageID||".png>" image,'+
'FROM '+
' images '+
'ORDER BY '+
' last_modified DESC '+
'LIMIT '+
' 25;'
);We can call it by passing in the URL as an SQL parameter. Here, we're swapping the endpoint name in the calling URL for the endpoint this appears in (GetManyImages) for the endpoint that serves up the images (GetOneBinaryImage).
// For image links, we'll need to point them to the alternate Endpoint
URL := TXdataOperationContext.current.Request.URI.AbsoluteURI;
URL := Copy(URL,1,Pos('GetManyImages',URL)-1)+'GetOneBinaryImage?ImageID=';
Query1.ParmByName('URL').AsString := URl;Now, our JSON will look something like this. We could actually just pass back the JSON without the URL and build the URL on the client, as all we really need for this is the ImageID value, but the idea here is that we can pass back a URL to the client in the same way as we were doing previously, and the client will work without requiring any changes at all.
[...
{"ImageID":1234,"Desc":"<img src=\"https://xdata.example.com:12345/SomeService/GetOneBinaryImage?ImageID=1234\">"},
...]
Now, when the client adds these <img> tags to the page, the browser will, in the background issue 25
separate requests, potentially using many threads, and populate the images as they return.
We get a few significant benefits here. Multithreading means that the same 25 MB will get transferred in much less time. The
page will begin updating as soon as the original, say, 3KB of JSON arrives, even before any image data at all has been received, rather than having to wait for the 25th consecutive
image to arrive. And our application will continue its own processing as soon as the JSON is
received, rather than having to wait for the large JSON block. This means that, even without any image data
having been received at all, we can still lay out the images ahead of time in preparation. As the images arrive, they will automatically be populated on the page. With a fast enough connection, this will work exceedingly well.
We could already do this if we had another web server serving up images, as we've discussed previously. But in this case, we've done the same thing just using the same XData server we were using already. No need for any additional web server configuration at all. And with no change to the client software needed, we could implement this anytime we like, and get a pretty substantial boost in app performance.
But we can do better!
Caching Images
When storing image data directly in the database, there is naturally a need to access the database to get the image data out. And, historically, databases and images were not a particularly great match, particularly when compared to the performance of a regular run-of-the-mill file server or even a web server. Databases have improved over the years, and as we need to access the database anyway to figure out which images we want, this isn't necessarily a problem as it once was.
But if we're requesting a bunch of images at once, that can put a strain on even the best-performing databases. So how might we retain all the benefits we've just acquired, but increase the performance to overcome this potential database bottleneck? Well, we can "cache" the images, removing the need for any database access at all, at least for the GetOneBinaryImage endpoint, which is the one most heavily impacted by database access times.
In fact, we can kind of come full circle and have the XData server generate a cache all on its own, replicating to a large degree what we might have created if we had set up a separate web server just for the images. When a request for an image comes in, we can first look to see if it is in the cache, potentially without even having to do a database lookup at all. If it is, we serve it up and call it a day. If it isn't, we add it to the cache and return the image at the same time.
In this scenario, the cache is just a folder on disk that we can use for storage, accessible from XData. We might set a JSON value in a configuration file to indicate where the cache is located so that it has ample space if the XData server itself is running in a location that isn't so lucky. Or we could specify a location that is faster (or slower) depending on just how many images we're serving and how fast it needs to be.
So now our GetOneBinaryImage endpoint just does a check to see if an image is available, and returns it if it is. And if it isn't, it creates a binary copy of whatever is in the database, stores it in the cache, and then returns the binary image just as it normally would have. After someone has accessed the image for the first time, it will be added to the cache so the next person won't have to wait for the database access delay.
But we
can do better still!
Generating Thumbnails.
What if, instead of just storing the image data in a cache, we also create thumbnails of each of the images, and make those available upon request using the same endpoint? When we create the image cache entry, we can also resize the image and save a thumbnail version. When the GetOneBinaryImage request arrives, we can check if the request is for the original image or the thumbnail, and return the appropriate file if it is in the cache, or do the same as before, generating any cache misses and returning the appropriate image while updating the cache at the same time.
Let's take our 25-image example. Perhaps instead of getting a list of images to return, we can instead return a
list of the same images but indicate that a thumbnail should be used. Say, the same image name, but with a _tn
suffix after the filename but before the file type extension. As in "imageid_tn.png". We could then adjust the
SQL query above to return the same name but with the _tn modification. If the client had a "viewer" function,
then it could remove the "_tn" modification and instead request the original image file, all handled just by
changing the URL that is assigned to the src parameter.
This is, in fact, what has been implemented for our Chat page in the Template project. For the cache, we've
set a configuration JSON parameter to indicate where the cache images are stored. When the XData server starts
up, it outputs a little bit of information about that cache using the following code. Let's assume that the
"Cache Folder" value in the configuration JSON is set to "C:/Data/Cache". The slashes are "backward" so that
it doesn't mess up the JSON.
// Cache Folder
if (AppConfiguration.GetValue('Cache Folder') <> nil)
then AppCacheFolder := (AppConfiguration.GetValue('Cache Folder') as TJSONString).Value
else AppCacheFolder := GetCurrentDir+'/cache';
if RightStr(AppCacheFolder,1) <> '/'
then AppCacheFolder := AppCacheFolder + '/';
if not(ForceDirectories(AppCacheFolder))
then mmInfo.Lines.Add('ERROR Initializing Cache Folder: '+AppCacheFolder);
if not(ForceDirectories(AppCacheFolder+'images'))
then mmInfo.Lines.Add('ERROR Initializing Cache Folder: '+AppCacheFolder+'images');
if not(ForceDirectories(AppCacheFolder+'images/ai'))
then mmInfo.Lines.Add('ERROR Initializing Cache Folder: '+AppCacheFolder+'images/ai');
if not(ForceDirectories(AppCacheFolder+'images/people'))
then mmInfo.Lines.Add('ERROR Initializing Cache Folder: '+AppCacheFolder+'images/people');
CacheFolderDirs := FloatToStrF(Length(TDirectory.GetDirectories(AppCacheFolder,'*',TsearchOption.soAllDirectories)),ffNumber,8,0);
CacheFolderList := TDirectory.GetFiles(AppCacheFolder,'*.*',TsearchOption.soAllDirectories);
CacheFolderFiles := FloatToStrF(Length(CacheFolderList),ffNumber,8,0);
CacheFolderSize := 0;
for i := 0 to Length(CacheFolderList)-1 do
CacheFolderSize := CacheFolderSize + (FileSizeByName(CacheFolderList[i]) / 1024 / 1024);
mmInfo.Lines.Add('...Cache Folder: '+AppCacheFolder);
mmInfo.Lines.Add('...Cache Statistics: '+CacheFolderDirs+' Folders, '+CacheFolderFiles+' Files, '+FloatToStrF(CacheFolderSize,ffNumber,8,1)+' MB');
From this, we get a little status message with the XData server starts. If you happen to have a huge image
cache with millions of entries, it might be good to skip this as it would take a while to generate the total
storage. But it is good to keep an eye on that in case your image cache gets out of hand. In our particular
design, we could delete the cache at any time, and it would automatically regenerate as needed, introducing only
a small delay for the first time when retrieving each image not already in the cache (for each cache miss). We could also add a
script somewhere to delete outdated cache entries or those that have not been accessed for a certain period of
time if it were necessary to control the size of the cache.
...Cache Folder: C:/Data/Cache/ ...Cache Statistics: 17 Folders, 76 Files, 29.2 MB
Our fancy endpoint that returns an image and generates cache entries for both the original and thumbnail
entries looks like this. Note that we're always doing at least one database access in this endpoint, so as to log the
endpoint activity in general. Which we probably don't need, but good to see at least initially. In a production environment, we might not bother with this, as a trade-off to increase performance.
The cache is
set up within an "ai" folder, and then within subfolders generated from the last three digits of the ImageID. This is so that we don't end up with a single folder with tens of thousands or millions of files. Windows
doesn't much like that. But this gets us a thousand folders, potentially, so if each of those has a thousand
images, we're at a million and can probably afford to revisit this if it causes any problems.
function TChatService.GetChatImage(F: String): TStream;
var
CacheFolder: String;
CacheFile: String;
CacheFileThumb: String;
SearchIndex: String;
SearchFile: String;
SearchStatus: String;
ReturnThumb: Boolean;
DBConn: TFDConnection;
Query1: TFDQuery;
DatabaseName: String;
DatabaseEngine: String;
ElapsedTime: TDateTime;
ImageString: String;
ImageBytes: TBytes;
ImageThumb: TPNGImage;
ImageBitmap: TBitmap;
begin
ElapsedTime := Now;
SearchStatus := 'Unknown';
// Setup DB connection and query
// NOTE: Image access is anonymous, but database access is usually not,
// so we should be careful how and when this is called
try
DatabaseName := MainForm.DatabaseName;
DatabaseEngine := MainForm.DatabaseEngine;
DBSupport.ConnectQuery(DBConn, Query1, DatabaseName, DatabaseEngine);
except on E: Exception do
begin
MainForm.mmInfo.Lines.Add('['+E.Classname+'] '+E.Message);
raise EXDataHttpUnauthorized.Create('Internal Error: CQ');
end;
end;
// Returning an Image, so flag it as such
TXDataOperationContext.Current.Response.Headers.SetValue('content-type', 'image/png');
// These don't really expire, so set cache to one year
TXDataOperationContext.Current.Response.Headers.SetValue('cache-control', 'max-age=31536000');
// Where is the Cache?
CacheFolder := MainForm.AppCacheFolder+'images/ai/';
// Is a Thumb being requested?
SearchIndex := StringReplace(F, '_tn.png','',[]);
SearchIndex := StringReplace(SearchIndex, '.png','',[]);
CacheFile := CacheFolder + Copy(SearchIndex,Length(SearchIndex)-5,3) + '/' + SearchIndex + '.png';
CacheFileThumb := CacheFolder + Copy(SearchIndex,Length(SearchIndex)-5,3) + '/' + SearchIndex + '_tn.png';
if Pos('_tn.', F) > 0 then
begin
ReturnThumb := True;
SearchFile := CacheFileThumb;
end
else
begin
ReturnThumb := False;
SearchFile := CacheFile;
end;
// We've got a cache hit
if FileExists(SearchFile) then
begin
SearchStatus := 'Hit';
Result := TFileStream.Create(CacheFile, fmOpenRead);
end
// Cache miss
else
begin
SearchStatus := 'Miss';
// Retrieve Image from Database
{$Include sql\ai\imageai\imageai_retrieve.inc}
// If thumbnail is requested, that's fine, but the original is what is stored in the database
// so let's get that first, and then generate the image and thumbnail cache, and then return whatever
// was originally requested.
Query1.ParambyName('CHATID').AsString := SearchIndex;
try
Query1.Open;
except on E: Exception do
begin
MainForm.mmInfo.Lines.Add('['+E.Classname+'] '+E.Message);
DBSupport.DisconnectQuery(DBConn, Query1);
raise EXDataHttpUnauthorized.Create('Internal Error: IAIR');
end;
end;
if (Query1.RecordCount <> 1) then
begin
DBSupport.DisconnectQuery(DBConn, Query1);
raise EXDataHttpUnauthorized.Create('Image Not Found.');
end;
// Generate Regular Cache Entry - Decode Base64 Image
ImageString := Query1.FieldByName('generated_image').AsString;
ImageBytes := TNetEncoding.Base64.DecodeStringToBytes(Copy(ImageString,33,length(ImageString)-34));
// Return binary file as the result
Result := TMemoryStream.Create;
Result.WriteBuffer(Pointer(ImageBytes)^, Length(ImageBytes));
// Save the binary file to the cache
if (ForceDirectories(System.IOUtils.TPath.GetDirectoryName(CacheFile)))
then (Result as TMemoryStream).SaveToFile(CacheFile);
// Create a thumbnail version: File > PNG > BMP > PNG > File
ImageThumb := TPNGImage.Create;
ImageThumb.LoadFromFile(CacheFile);
ImageBitmap := TBitmap.Create;
ImageBitmap.width := 92;
ImageBitmap.height := 92;
ImageBitmap.Canvas.StretchDraw(Rect(0,0,92,92), ImageThumb);
ImageThumb.assign(ImageBitmap);
ImageThumb.SaveToFile(CacheFileThumb);
if ReturnThumb
then (Result as TMemoryStream).LoadFromFile(CacheFileThumb);
ImageThumb.Free;
ImageBitmap.Free;
end;
// Keep track of endpoint history
try
{$Include sql\system\endpoint_history_insert\endpoint_history_insert.inc}
Query1.ParamByName('PERSONID').AsInteger := 1; // Default admin user
Query1.ParamByName('ENDPOINT').AsString := 'ChatService.GetChatImage';
Query1.ParamByName('ACCESSED').AsDateTime := TTimeZone.local.ToUniversalTime(ElapsedTime);
Query1.ParamByName('IPADDRESS').AsString := TXDataOperationContext.Current.Request.RemoteIP;
Query1.ParamByName('APPLICATION').AsString := MainForm.AppName;
Query1.ParamByName('VERSION').AsString := MainForm.AppVersion;
Query1.ParamByName('DATABASENAME').AsString := DatabaseName;
Query1.ParamByName('DATABASEENGINE').AsString := DatabaseEngine;
Query1.ParamByName('EXECUTIONMS').AsInteger := MillisecondsBetween(Now,ElapsedTime);
Query1.ParamByName('DETAILS').AsString := '['+F+']['+SearchStatus+']';
Query1.ExecSQL;
except on E: Exception do
begin
MainForm.mmInfo.Lines.Add('['+E.Classname+'] '+E.Message);
DBSupport.DisconnectQuery(DBConn, Query1);
raise EXDataHttpUnauthorized.Create('Internal Error: EHI');
end;
end;
// All Done
try
DBSupport.DisconnectQuery(DBConn, Query1);
except on E: Exception do
begin
MainForm.mmInfo.Lines.Add('['+E.Classname+'] '+E.Message);
raise EXDataHttpUnauthorized.Create('Internal Error: DQ');
end;
end;
end;
Note that as this endpoint will not require authorization, we won't have a JWT to use for database
access. So we'll use a "system" account of some type, both for accessing the images and for logging the
endpoint activity. If we wanted to ensure that the images were used by someone logged in at the time, we could
cheat a little and require that the IP of the request be associated with a current JWT. This is another way to
skirt around how browsers don't provide an authorization mechanism when requesting images. But as we discussed,
even this might be onerous when it comes to sharing images. However, it's an option, and we like to have options.
Speaking of options, one of the hard-coded choices above was the size of the thumbnails - set at 92px by 92px. Seems kind of arbitrary? Well, that just happens to be the size of the images when they appear in the "Recent Activity" section of the Chat page. Of course, any image size could be used here. And we're not limited to one.
When the Actorious app retrieves images from The Movie Database image servers, there are several sizes
available, from very small thumbnails to very large poster photos, with several steps between. Ideally, we'd
have the exact size we need, ready to go, whenever it is requested. In our Chat app, there are just two sizes
that have come up (so far!) so we just have those two sizes available (thumbnail and original size).
Over in the client app, our original endpoint request will now get us a list of thumbnail images that we can
populate as we've been doing. The client might not even notice that the images are thumbnails now, as there's
no change required. However, in this application, we also have a "viewer" option - when clicking on one of the
images, we'd like to see a full-screen version. Previously, we'd just display the same image in the viewer as
we had originally retrieved (by whatever means). Now, we just need to make a small alteration to swap out the
thumbnail version for the full-size version. Just a simple search and replace to remove the "_tn" suffix is all
that is required.
ImageRecent.addEventListener('click', (e) => {
if (e.target.parentElement.classList.contains('ViewableImage')) {
e.stopImmediatePropagation();
pas.UnitMain.MainForm.Viewer(e.target.parentElement.outerHTML.replaceAll('_tn.png','.png'));
}
})
And with that, we've got our thumbnails flowing into the main display, and the original images showing up in
the viewer. If the user never clicks on any of those images, then we don't have to worry about downloading any
of them. And if they come back to this page often, the browser would have cached all the thumbnails up until
their last visit, so only new images would need to be downloaded, and only thumbnails at that. Those come in at
around 20 KB. So even if we had 100 thumbnails, they would use up less network traffic than one 1024x1024
image.
But wait, we can do even better than that.
Browser Caching.
An astute reader might have picked up on another cache-related item in the above code. This has nothing to do with XData or our newly minted image cache. We just touched on it briefly - the browser cache. Whenever a browser downloads a file on its own using its multithreaded approach that ignores all our hard authorization work, it at least does us a favor and adds the image to its own cache.
This cache is built using the URL of the
image as an index (likely a hashed version, I'd wager). The next time it needs that image, it checks to see if
it is in its own cache. If so, it doesn't even make a request for the image - it just loads the image from the
cache. And, as you can imagine, thumbnails load up particularly quickly. So quickly that they might all be
loaded by the time the page is initially displayed.
This is of course pretty great, and one of the reasons why we might want to use a URL for an image rather than
a Data URI. Generally, Data URIs are not cached in any meaningful way, so they may not be the best choice in
some cases. But the regular image URLs are cached aggressively. The question, then, is for how long? The
defaults may depend on the browser, how much local space is available for the cache, and how recently the page (and
the image) was last visited. So it can vary quite a lot. To remove the mystery, we can actually set an age
explicitly, and that's what this little line of code is doing.
// These don't really expire, so set cache to one year
TXDataOperationContext.Current.Response.Headers.SetValue('cache-control', 'max-age=31536000');This requests that, for each image we're serving up from our cache, the browser should add it to its own cache for up to one year. This is a commonly used value, even if the data is never really going to expire. If you have a huge static image archive and a huge user base, you might want to set it even longer. Note that, when this value is set, the browser will aggressively cache these images. This means that if you're testing the performance of your image cache generation from the client's perspective, you'll have to use the "Empty Cache and Hard Reload" option in order to not have the browser's cache display the images you're testing.
There are other headers and related caching options that can be employed here as well. Caching can be completely disabled. Or another approach, using ETag and last-modified headers, can be used to be more specific about when images should be revalidated. Whatever your particular caching needs might be, there's very likely an option that can be tailored to suit.
So now we have our images cached in multiple places. We've optimized the size of images and how they're ultimately transferred to the browser. And we can have our images 100% stored in the database or 100% not stored in the database, or perhaps both. And there's even a chance that we could load our page with absolutely no image data being transferred if it is all in the browser cache already. Seems like we're done, right?
Well, we can do one step
better still.
Let's Be Lazy.
Once upon a time, around Netscape 1.0, if we visited a website that was particularly slow, misconfigured, or just plain broken, we might see an image placeholder that looked like a broken picture. It was actually pretty common, come to think of it. And it could happen to any website, not just the less fortunate. Over the years, vast improvements in network speed and better website design have dramatically reduced the frequency with which these appear. They're still there, though, usually lurking just below the surface. A broken image might appear if the requested image was simply unavailable. Or it might appear if the web server was taking too long to provide it.
Sometimes this happened because the browser would request hundreds of images at a time, and it would just
take too long for them all to be delivered. Like if you had a really long page with a lot of images on it.
Maybe the first 20 would download fine, and the rest would be broken. Refreshing the page would maybe get
another 20 to download, reload the first 20 that were cached, and then the rest would be broken. Lather. Rinse. Repeat.
With faster download speeds, better network throughput, multi-threaded requests, appropriate use of thumbnails, and so on, the time taken to download a large number of images has been reduced to below what a typical timeout might be today. But another key development is the support for "lazy loading" of images. Browsers are a little smarter now. If a page has a lot of images on it, but some are not displayed on a part of the page that is currently visible to the user, it will defer trying to download them.
What does "currently visible" mean? Well, it can mean that
they are further down the page than the user has scrolled so far. Or they could be hidden in another panel that
is not currently showing. Or they could be images embedded in each row of a table, and only a few rows of the
table are currently showing. When the user works their way down the page, clicks a tab to show a previously
hidden panel, or scrolls down a long table, images that were previously obscured become visible, and the browser
steps in and starts downloading the images.
Sometimes, this lazy loading happens so quickly that it appears that everything is already loaded. Sometimes
it isn't so quick, and you can see the images filling in as you're scrolling. This all depends on how big the
images are, how many of them are being loaded dynamically, how many have been cached, and so on. Lots of
potential issues. But generally, this has worked pretty well. So well that current browsers all offer support
for lazy loading by adding the "loading" attribute with a value of "lazy".
<img loading="lazy" src="https://example.com/image/test.jpg">
There may be variations on when the lazy factor kicks in. Ideally, as the user is scrolling through a page, the upcoming images will be loaded before the user gets to them, giving the illusion that everything is already loaded. In practice, this may not always work, but often the loading is so fast that it doesn't cause problems. Some content can be scrolled by dragging the scrollbar, so it isn't necessarily reasonable that all images would always be loaded before they make it onto the screen. This brings up the next item of business. What do we want to happen when an image is not yet available?
Even in modern browsers, scrolling too quickly, or loading really large images, may take time. While we're waiting, what should happen? It would probably be best if we had a placeholder image that fits in with our theme, maybe even our brand, that could be shown while we were waiting for an image to download. And perhaps better yet, if we already have a thumbnail available, we could show that image as a placeholder while we're waiting for a larger version to materialize. But now we're beyond what is typically available in the default browser attributes and well into the realm of JavaScript libraries.
And if you're having a sense of deja vu it is likely because we have indeed covered this exact topic before - in the Tabulator post about performance, which can be found here. The gist of it is that we're going to need a JavaScript library, like Vanilla Lazy Load, to help us out.
We can add a block of code to our project that will actively monitor the arrival of new images on our page. We'll need to add a class of "lazy" to our <img> elements, and we'll need two "src" attributes. The default "src" attribute will be used for the placeholder image, and the "data-src" attribute will be used for the actual image we want to display. If we're just displaying thumbnails, we can point the "src" attribute at a generic placeholder image of our choosing. If we're displaying a larger image where we already have a thumbnail, the "src" attribute will point at the thumbnail and the "data-src" attribute will point at the larger image.
First, we'll need the JavaScript library. The Vanilla Lazy Load library can be added to our Project.html as
usual. It is currently ranked as the 18th most popular JavaScript library on the JSDelivr CDN. Pretty solid
library.
<script src="https://cdn.jsdelivr.net/npm/vanilla-lazyload@17.8.3/dist/lazyload.min.js"></script>
Then, we'll need to add a block of less-than-friendly Javascript. This sets up the mechanism that watches for new <img> tags appearing on our page, called a MutationObserver. Some variation on this can be found in the Vanilla Lazy Load documentation.
// Lazy Load images via Vanilla Lazy Load
asm
// This sets up our image lazy loading system. Just need to add "lazy" as
// a class to an <img> tag and, oddly, to make sure that when adding it via
// innerHTML, that it is enclosed in a <div> tag
window.lazyLoadInstance = new LazyLoad({});
var observer = new MutationObserver(function(mutations) {
var image_count = 0;
mutations.forEach(
function(mutation) {
for (var i = 0; i < mutation.addedNodes.length; i++) {
if (typeof mutation.addedNodes[i].getElementsByClassName !== 'function') {return;}
image_count += mutation.addedNodes[i].getElementsByClassName('lazy').length;
}});
if (image_count > 0) {
window.lazyLoadInstance.update();
}});
var config = { childList: true, subtree: true };
observer.observe(document.documentElement, config);
end;And finally, we'll need to add the "lazy" class to our images and set up the src and data-src attributes appropriately. For the images that are coming from our image AI, we can do this via the following.
for (var i = 0; i < data['ImageAI Recent'].length; i++) {
ImageRecent.innerHTML += '<div class="cursor-pointer ViewableImage" title='+data['ImageAI Recent'][i].prompt+'>'+
(data['ImageAI Recent'][i].generated_image).replace('<img src=','<img class="lazy" data-src=').replace('>',' ')+
' src="assets/placeholder92.png" >'+
'</div>';
}
For some reason, these didn't automatically load, so the extra call by "window.lazyLoadInstance.update()" can be used to trigger the lazy loading mechanism any time we make a bunch of changes at one time. The same approach is used to apply these changes to the thumbnail when it is displayed in the viewer. But as we were lazy and just copied the HTML, we have to do a bit more work here to 'reset' the lazy status of the image, swap in the non-thumbnail version, and get it ready for a new lazy effort.
ImageRecent.addEventListener('click', (e) => {
if (e.target.parentElement.classList.contains('ViewableImage')) {
e.stopImmediatePropagation();
var img = e.target.parentElement.outerHTML;
img = img.replace('lazy entered loaded','lazy');
img = img.replace('data-ll-status="loaded"','');
img = img.replace('_tn.','.');
pas.UnitMain.MainForm.Viewer(img);
window.lazyLoadInstance.update();
}
});
Now any images that aren't visible and are not yet cached will not be loaded until they are needed. And if we
happen to spot them on the screen before they've been downloaded, we'll see a nice placeholder (in the case of
thumbnails) or the thumbnail (in the case of large images).
All Done!
If you want to see what this looks like with a large number of images, head over to the Actorious website and scroll around. This is a TMS WEB Core project that uses the Vanilla Lazy Load library. The image links come from an XData server. The image data comes from a remote CDN web server. The initial page, when it first loads, has about 200 images immediately visible. If you scroll both the left and right lists, you'll probably end up loading around 1,000 thumbnails.
You can scroll faster than the images can load, but it catches up quite quickly. The tabs at the
top have considerably larger images (and videos in many cases), which are almost always loaded faster than the scrolling speed. Note that the mouse wheel
scrolls the left and right tables up/down, and the top photos and posters left/right, so you can move around
pretty quickly. Here's a video showing exactly this.
And with that, we've got our bases pretty well covered as far as handling database images in our TMS WEB Core projects. What do you think? Did I miss anything? Is there more to the story? I'm sure there is! As always, please post any questions or comments below.
Follow Andrew on 𝕏 at @WebCoreAndMore or join our 𝕏 Web Core and More Community.
Andrew Simard

This blog post has received 8 comments.
 2. Friday, May 12, 2023 at 6:38:17 PM
I think you have a number of options, depending on what kind of UI you are after. I am generally not a big fan of paging, but it has its uses. The basic idea promoted in this post is to have the thumbnails available in advance (which you do), and then pass references to them (links) so that you can quickly send over hundreds or even thousands of links in just a few KB. Then let the browser do its thing, displaying (and caching internally) only the images that make it onto the page, visible to the user, using lazy loading of whatever flavor you like. You don''t even need a component - just a DIV element with a bit of styling for how you want the thumbnails to look. Then if someone clicks on a thumbnail, download the full version. Having an XData endpoint that can resolve a URL to a database-supplied (or XData cached) image, thumbnail or otherwise, makes quick work of this. The question of whether the XData cache is necessary depends on how often the images are accessed by different people, and how quick your database can sever them versus a cached version.
2. Friday, May 12, 2023 at 6:38:17 PM
I think you have a number of options, depending on what kind of UI you are after. I am generally not a big fan of paging, but it has its uses. The basic idea promoted in this post is to have the thumbnails available in advance (which you do), and then pass references to them (links) so that you can quickly send over hundreds or even thousands of links in just a few KB. Then let the browser do its thing, displaying (and caching internally) only the images that make it onto the page, visible to the user, using lazy loading of whatever flavor you like. You don''t even need a component - just a DIV element with a bit of styling for how you want the thumbnails to look. Then if someone clicks on a thumbnail, download the full version. Having an XData endpoint that can resolve a URL to a database-supplied (or XData cached) image, thumbnail or otherwise, makes quick work of this. The question of whether the XData cache is necessary depends on how often the images are accessed by different people, and how quick your database can sever them versus a cached version.
Andrew Simard
3. Sunday, May 14, 2023 at 8:46:41 AM
Thanks Andrew,. With web development you certainly have to experiment to find the best way for a specific solution.
Randall Ken
4. Sunday, May 14, 2023 at 7:47:20 PM
That is only because we now have so many better ways to accomplish the same task. Great to have options!
Andrew Simard
5. Sunday, May 21, 2023 at 8:55:57 AM
I am having great problems using a similar mechanism to access database images after implementing JWT authorization. Have you tried this?
Randall Ken
6. Sunday, May 21, 2023 at 11:56:09 AM
Yes, it will work fine if you are just accessing it like any other data, using the normal mechanisms you usually use to access an XData endpoint. If, however, you are trying to use the link approach I have outlined, it is actually the browser making the request. In this scenario, the browser does not pass credentials of any kind, so the JWT isn''t available. I will follow up with some other ideas in your TMS Support Center post here: https://support.tmssoftware.com/t/use-of-txdataserver-events/20973
Andrew Simard
7. Monday, August 21, 2023 at 5:58:19 PM
Thanks Andrew, I have implemented some of the code here to allow the retrieval of an image from a service in XData, I would like to extend this by having a endpoint that could generate a barcode and send the image back, do you know of the best way to generate a barcode from inside xdata?Burton Richard
8. Monday, August 21, 2023 at 7:31:37 PM
As XData is typically just a Delphi VCL app, you can use whatever Delphi tools are available for this. For example, the TMS FNC WX Pack contains TTMSFNCWXBarcode / TTMSFNCWXQRCode components that might work for this. I''ve also used Zint with great success in past projects: https://github.com/landrix/Zint-Barcode-Generator-for-Delphi. Check out this discussion for some hints: https://en.delphipraxis.net/topic/6894-zint-barcode-studio-zintdll/
Andrew Simard
All Blog Posts | Next Post | Previous Post
Very interesting as usual. I''m rewriting one of my VCL apps in Web Core. It is a very large application for estate agents and I have one form where they need to be able to display all images for a property and add new ones. the images can be pretty large but I have them stored in a table as both the original and a resample smaller image. The VCL app includes the ability to edit them but I may skip that. They are accessible via an XData server and am accessing it mainly as an OData store so that they can be paged. I am looking for the best way of displaying them. Any ideas. I haven''t used any visual components so far as I prefer to use DevExtreme.
Regards,
Ken
Randall Ken